
-
CENTRES
Progammes & Centres
Location
English dominates the Internet. But as the next billion swarm online from the developing world, access to relevant content in a language one comprehends will be crucial.

English dominates the Internet. It accounts for more than half of all written content online although only less than 16 percent of the global population speaks the language. Cyberspace represents an extraordinarily truncated snapshot of the world’s linguistic diversity. The United Nations Educational, Scientific and Cultural Organization (UNESCO) says there are 8,324 written and spoken languages, of which around 7,000 are still in use. But in the online universe, besides English, only around eight languages have a significant presence. On World Telecommunication and Information Society Day, observed annually on 17 May, it is worth taking stock of these information inequities, and exploring how we might build more linguistically diverse and inclusive information societies.
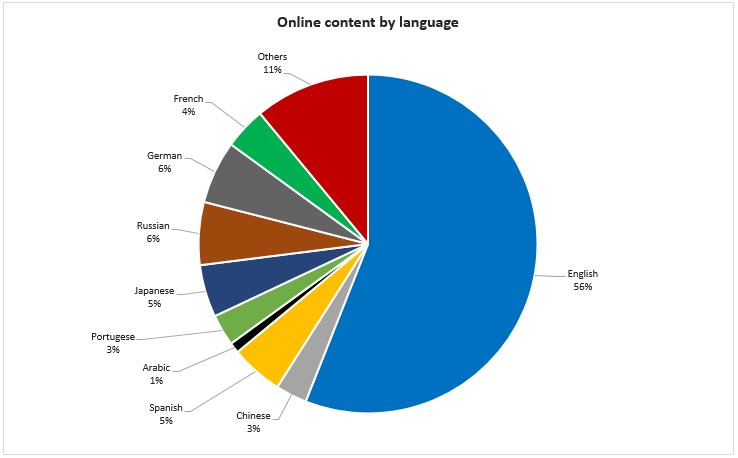
Source: Statista
How did we get here? The early development of the Internet in the United States and other English-speaking countries meant that many of its early adopters were English speakers. The US’s continuing role as a global tech leader has played a part in entrenching English’s dominant position online. As the Internet Society Foundation observes, there is a “self-reinforcing cycle where more content available in English attracts more users, leading to the further expansion of English language content”. Consequently, the barrier for other languages to gain similar traction, visibility and reach has grown more insurmountable.
The lack of multilingualism in cyberspace has widened digital divides, and resulted in the neglect of large swathes of humanity.
The status quo is no longer tenable. As the next billion swarm online from the developing world, access to relevant content in a language one comprehends will be as crucial as access to technology itself. Historically, the lack of multilingualism in cyberspace has widened digital divides, and resulted in the neglect of large swathes of humanity. Strategic investments must therefore be made in language technology; and advances in machine translation, digital scripts, and natural language processing must be matched by offline efforts to boost language education and competencies. Indeed, raising awareness about the importance of linguistic diversity is a first step towards more interconnected and equitable digital environments.
Nearly 25 years ago, participants at a meeting of the Internet Corporation for Assigned Names and Numbers (ICANN) in Cairo, Egypt, drew attention to the need for non-English domain names. A decade passed before ICANN began to set up and test internationalized domain names (IDNs). There has been much progress since. In India, for instance, ICANN has been working to support domain names in multiple languages used across the country, including its 22 scheduled languages. Concomitantly, the organization is establishing guidelines to define top-level domains (TLDs) securely and reliably across Indian and other languages globally, so that non-English speakers can access websites that use domain names written in their native scripts, rather than having to depend exclusively on English-based domain names.
In 2014, the Indian government launched the ‘Bharat’ domain name in Devanagari script, covering eight languages including Hindi, Konkani, and Marathi. That allowed individuals or companies interested in owning a website with a Hindi domain name to book its name with a ‘Bharat’ extension in the Hindi script, rather than the more common TLDs such as ‘.com’, ‘.net’ or ‘.in’. The following year, the National Internet Exchange of India launched IDNs in other Indian languages such as Bangla, Manipuri, Urdu, Punjabi, Telugu, Tamil, and Gujarati.
All mobile devices would have to adhere to certain standard character sets for every language.
In a major stride forward, between 2017 and 2018 the government—supported by the Bureau of Indian standards and language experts—mandated that all smartphones and featurephones in the country would have to support Indic text. Additionally, all mobile devices would have to adhere to certain standard character sets for every language. This was critical as different devices had hitherto used different character sets, leading to inconsistencies in the way the text was rendered on each device.
Compliance with this mandate has had an electric effect on Internet and mobile use in mobile-first India, and has catalysed the growth of Indic language content and services to an unprecedented degree. According to a Google-KPMG survey, there is a high demand for Indian-language services among the country’s Internet users, most of whom would prefer to use the Internet in their own language. Today, with compulsory display support for 22 Indian languages on mobile devices, Internet access in local languages has become a reality for millions of Indians.
Complementing these efforts, the private sector has thrown its weight behind the development of multilingual platforms and content. For example, e-commerce giants Flipkart and Amazon have launched websites in regional languages; and social media platforms like Facebook, Whatsapp, and X support several Indian languages.
Generative AI startup Sarvam, which was founded in 2023 and built its system using available open-source models, launched OpenHathi, its first open-source Hindi LLM, and has already raised US$ 41 million in funds.
The growing availability of data and content in vernacular languages is shaping the progress of India’s artificial intelligence (AI) sector as well. For instance, Krutrim, India’s first US$ 1 billion AI startup—founded by serial entrepreneur Bhavish Aggarwal—has launched the country’s first multilingual large language model (LLM), which can generate text in 10 Indian languages. Krutrim’s LLM is voice-enabled, and can understand several languages, including a mix of languages such as Hindi and English, popularly referred to as “Hinglish”. Generative AI startup Sarvam, which was founded in 2023 and built its system using available open-source models, launched OpenHathi, its first open-source Hindi LLM, and has already raised US$ 41 million in funds. Similarly, the Telugu LLM Labs have unveiled Navarasa 2.0, an upgraded LLM supporting 15 Indian languages and English, with a view to promoting digital inclusivity and accessibility; and OdiaGenAI has built an LLM to address the linguistic nuances of Odia and to strengthen the language’s digital presence.
At the apex of all these public and private projects and enterprises is the government’s “Mission Bhashini”. Launched in 2022, the Mission is building an Indian language tech ecosystem, bringing together under a single framework the various efforts by government, academia and startups for developing Indic language technologies, and to create a Unified Language Interface (ULI) for Indian languages.
Even as India consolidates its web development efforts and creates new content, scripts and AI solutions to advance linguistic inclusion, there is more that could be done. With more businesses beginning to see multilingual content as a means to explore untapped markets, reach broader audiences, and generate higher revenue, it is likely that initiatives in the space will attain greater pace and scale. This, along with a sustained governmental push, will be necessary for addressing the scarcity of quality language data in non-English languages compared to English. The issue of scarcity currently hinders the development of algorithms and AI models for natural language processing in Indian languages, making the automation of translation and content creation processes difficult.
With more businesses beginning to see multilingual content as a means to explore untapped markets, reach broader audiences, and generate higher revenue, it is likely that initiatives in the space will attain greater pace and scale.
Capitalising on the proven demand for local language content will be essential. In this regard, interventions like the National Translation Mission which aims to popularise the use of Indian languages in the fields of science, tech, business and administration are of immense value. So are the Digital India programmes that have resulted in language-specific portals, digital libraries for Indian-language resources, and digital literacy drives benefiting large segments of the population. Collectively, these actions are helping craft more diverse information and knowledge societies.
Anirban Sarma is a Deputy Director and Senior Fellow at Observer Research Foundation
Shrushti Jaybhaye was a Research Intern at Observer Research Foundation
The views expressed above belong to the author(s). ORF research and analyses now available on Telegram! Click here to access our curated content — blogs, longforms and interviews.

Anirban Sarma is Director of the Digital Societies Initiative at Observer Research Foundation (ORF). He is presently a Lead Co-Chair of the Think20 Brazil Task ...
Read More +
Shrushti Jaybhaye is a Research Intern at the Observer Research Foundation ...
Read More +


